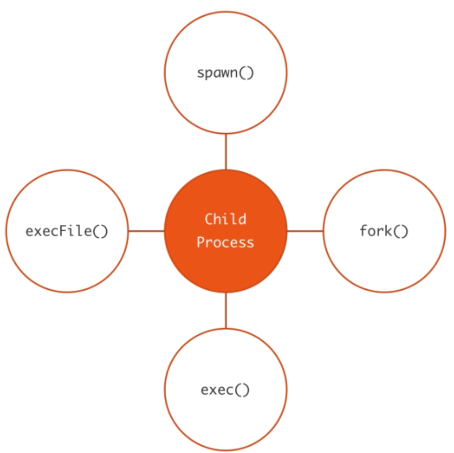
具体用法参考官方文档即可,已经写的很清楚。本文仅做一些简单对比。
简单对比 方法 spawn fork exec execFile 是否通过 shell 执行子命令 否(*) 否 是 否(*) 读取程序输出 利用子进程的 stdout / stderr 利用子进程的 stdout / stderr 在 callback 中一次返回 在 callback 中一次返回 父子进程通信 process.send() 与 process.on("message") (仅当子进程为 Node 脚本时可用) process.send() 与 process.on("message") 不支持 不支持 备注 仅限执行 Node 脚本 说明 fork、exec、execFile 都是 spawn 的一种特殊情况,内部都是调用了 spawn 方法。 spwan 和 execFile 默认是创建子进程直接执行指定命令,但是可以通过 option 中的 shell 字段来明确要求在一个 shell 中执行命令。 由于 exec 和 execFile 会把子进程的 stdout 和 stderr 缓存起来一次性返回给调用方,在子进程退出之前,这些缓存数据会在内存中不断累积。为了防止内存占用过多导致的问题,这两个方法的参数对象中接受一个 maxBuffer 字段,表示缓存数据的上限大小,超过该大小会导致子进程被 kill() 且缓存数据会被截断。该参数的默认值是 1024 * 1024。 以上几个方法的源码都在 lib/child_process.

两个核心模块 require 和 module。
require 模块对应全局的 require 方法。module 模块对应每一个模块全局空间中的 module 属性。
Node.js 加载一个模块主要经历以下几个步骤:
Resolving -> Loading -> Wrapping -> Evaluating -> Caching
Resolving Node.js 中的模块和文件系统中的文件是一一对应的(这一点很重要)。加载模块的过程其实就是执行文件系统中的脚本并将结果载入内存的过程。
每一个模块都有一个 id 属性,该属性的值就是这个模块对应文件的绝对路径(在 REPL 里为 ““)。
Resolving 阶段的工作就是把我们 require 的字符串解析成一个文件系统中的绝对路径。根据我们 require 包的类型,这里又分为三种情况:
核心模块。也即 Node.js 内置的模块,例如 “fs”、”path”、”http” 等,这类模块无需安装即可直接使用。 相对路径/绝对路径。Node.js 直接将相对路径转换成对应的绝对路径。 第三方依赖。如果不是前两种情况,那么 Node.js 会依次查找 module.paths 列表中的目录是否存在。 我们来看看 module.paths 中都有哪些目录: 可以看到主要是从当前目录逐级向上查找 node_modules 目录。这也就是为什么我们的依赖会被安装在 node_modules 目录下的原因。 为了向前兼容,Node.js 还会检查一些已经被废弃的目录,不推荐使用它们。
在找到这个列表中某个存在的目录之后,Node.js 会在该目录下继续查找,假设我们执行的是 require("moduleA"),那么又可以分为以下三种情况:
存在一个 moduleA.js 文件,那么该文件就是最终我们要加载的文件。 存在一个 moduleA 子目录,且该目录下存在一个名为 index.