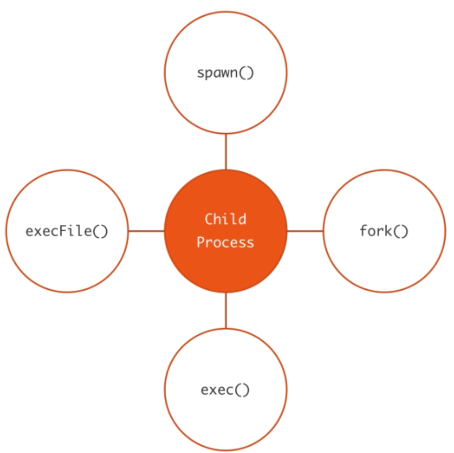
具体用法参考官方文档即可,已经写的很清楚。本文仅做一些简单对比。
简单对比 方法 spawn fork exec execFile 是否通过 shell 执行子命令 否(*) 否 是 否(*) 读取程序输出 利用子进程的 stdout / stderr 利用子进程的 stdout / stderr 在 callback 中一次返回 在 callback 中一次返回 父子进程通信 process.send() 与 process.on("message") (仅当子进程为 Node 脚本时可用) process.send() 与 process.on("message") 不支持 不支持 备注 仅限执行 Node 脚本 说明 fork、exec、execFile 都是 spawn 的一种特殊情况,内部都是调用了 spawn 方法。 spwan 和 execFile 默认是创建子进程直接执行指定命令,但是可以通过 option 中的 shell 字段来明确要求在一个 shell 中执行命令。 由于 exec 和 execFile 会把子进程的 stdout 和 stderr 缓存起来一次性返回给调用方,在子进程退出之前,这些缓存数据会在内存中不断累积。为了防止内存占用过多导致的问题,这两个方法的参数对象中接受一个 maxBuffer 字段,表示缓存数据的上限大小,超过该大小会导致子进程被 kill() 且缓存数据会被截断。该参数的默认值是 1024 * 1024。 以上几个方法的源码都在 lib/child_process.

一个正则表达式引发的空白 最近在开发内部的一个前端异常监控系统,在 Web 端会展示异常上报的来源 IP 以及所在地,大概是这个样子的:
由于页面空间有限且几乎所有的异常都来自国内,因此做了一个简单的优化,将所在地字符串开头处的“中国”二字移除掉,写个很简单的正则表达式即可:
result.replace(/^中国/, "") 改完以后,效果还不错:
直到有一天小伙伴反馈问题,有的 IP 的地理位置展示了空白,像这样:
简单调查了一下发现该 IP 的查询结果只有“中国”二字,于是经过前面的处理逻辑后就只剩下空字符串了。
解决方案 最直接的想法就是增加一个 if / else 判断,如果查询结果是“中国”二字,则跳过正则处理。
虽然直接,但是感觉不够简洁。能否在原来的正则表达式上优化一把来实现我们要的效果呢?使用今天要说的 lookahead 断言就可以。
lookahead 断言 在说 lookahead 断言前我们先看看另一个写法:
result.replace(/^中国./, "") 这种写法在“中国”二字后多匹配了一个字符,这样写可以避免处理仅有“中国”二字的情况,但带来一个新的问题:在多个字的情况下,多删掉了一个字符。
我们想要的只是一个 0 长度的断言而不是真正匹配什么内容,就像 \b,^,$ 那样,只表示某个条件是否达成,但并不匹配字符串中的内容。
这就是 lookahead 的意义,我们只需将正则改写成:
result.replace(/^中国(?=.)/, "") 就可以表示只匹配之后还有其它字符的“中国”二字的含义。
lookahead 断言的写法就是 (?=(regex)) 其中(regex) 就是你想断言的条件。
只需要将 = 改成 ! 你就得到了一个否定形式的 lookahead 断言,例如 /^中国(?!.)/ 就表示之后没有任何其它字符的“中国”二字。
lookbehind 断言 与 lookahead 对应的,还有 lookbehind 断言以及它的否定形式:
/(?<=(regex))/ /(?

几天前的 JavaScript Weekly 里推送了一条名为 “A Look at Deno: A New JavaScript Runtime” 的视频,视频的内容是 Deno 的作者(同时也是 Node.js 项目的最初发起人与维护者) Ryan Dahl 在今年 4 月初的 JS Fest 大会上做的关于 Deno 的演讲。
Deno, a new way to JavaScript 看完视频感觉这个项目挺有趣,于是花了一点时间做了一些了解,记录如下。

在函数中使用泛型 这里 T 可以代表任意类型。
function identity<T>(arg: T): T { return arg; } 使用时可以明确指定类型:
let output = identity<string>("myString"); 不过更多时候是交给 TypeScript 进行类型推断:
let output = identity("myString"); 在接口中使用泛型 interface GenericIdentityFn { <T>(arg: T): T; } function identity<T>(arg: T): T { return arg; } let myIdentity: GenericIdentityFn = identity; 我们还可以把泛型参数提升到整个接口的层面,像下面这样:
interface GenericIdentityFn<T> { (arg: T): T; } 然后在我们使用这个接口的时候,必须明确指定这个泛型参数的类型:
function identity<T>(arg: T): T { return arg; } let myIdentity: GenericIdentityFn<number> = identity; 我们得到的 myIdentity 方法只能接受数字作为参数。
函数类型 利用 interface 声明函数类型,只需要把接口定义中的属性写成函数签名即可。
像这样:
interface SearchFunc { (source: string, subString: string): boolean; } 如果我们的函数本身还有一些属性,例如 Node.js 中的 require() 方法,我们既可以 require("package") 又可以 require.resolve("package")。这是需要首先为该方法定义一个接口,然后再通过 extends 它来添加属性。
interface NodeRequireFunction { (id: string): any; } interface NodeRequire extends NodeRequireFunction { resolve: RequireResolve; cache: any; extensions: NodeExtensions; main: NodeModule | undefined; } 索引类型 有时我们想让我们对象支持向数组那样按照数字下标来存取数据,有时我们会想创建一个”字典”对象来存取任意的 “key/value” 对应关系。这两种情况就需要声明索引类型。区别在于索引本身的类型是数字还是字符串。
interface StringArray { [index: number]: string; } interface NameAddressMap { [index: string]: string; } 我们可以把一个对象声明成既支持字符串索引有支持数字索引:
interface ItsOK { [index: string]: string; [index: number]: string; } 如果我们的对象要同时支持两种索引类型,那么必须保证字符串索引对应值的类型是数字索引对应值的类型的超集。

两个核心模块 require 和 module。
require 模块对应全局的 require 方法。module 模块对应每一个模块全局空间中的 module 属性。
Node.js 加载一个模块主要经历以下几个步骤:
Resolving -> Loading -> Wrapping -> Evaluating -> Caching
Resolving Node.js 中的模块和文件系统中的文件是一一对应的(这一点很重要)。加载模块的过程其实就是执行文件系统中的脚本并将结果载入内存的过程。
每一个模块都有一个 id 属性,该属性的值就是这个模块对应文件的绝对路径(在 REPL 里为 ““)。
Resolving 阶段的工作就是把我们 require 的字符串解析成一个文件系统中的绝对路径。根据我们 require 包的类型,这里又分为三种情况:
核心模块。也即 Node.js 内置的模块,例如 “fs”、”path”、”http” 等,这类模块无需安装即可直接使用。 相对路径/绝对路径。Node.js 直接将相对路径转换成对应的绝对路径。 第三方依赖。如果不是前两种情况,那么 Node.js 会依次查找 module.paths 列表中的目录是否存在。 我们来看看 module.paths 中都有哪些目录: 可以看到主要是从当前目录逐级向上查找 node_modules 目录。这也就是为什么我们的依赖会被安装在 node_modules 目录下的原因。 为了向前兼容,Node.js 还会检查一些已经被废弃的目录,不推荐使用它们。
在找到这个列表中某个存在的目录之后,Node.js 会在该目录下继续查找,假设我们执行的是 require("moduleA"),那么又可以分为以下三种情况:
存在一个 moduleA.js 文件,那么该文件就是最终我们要加载的文件。 存在一个 moduleA 子目录,且该目录下存在一个名为 index.

前言 Yarn 团队在春节前公布了 Yarn 2.0 的规划。其中提到了一个之前没听说过的名词 “PnP”。发现 Yarn 的这个功能早在 18 年 9 月份就被提出并实现了。于是花了一些时间了解了一下它的工作原理以及解决的问题并整理除了本篇文章。
现状与痛点 Yarn 团队开发 PnP 特性最直接的原因就是现有的依赖管理方式效率太低。引用依赖时慢,安装依赖时也慢。
先说说 Node 在处理依赖引用时的逻辑,这个流程会有如下两种情况:
如果我们传给 require() 调用的参数是一个核心模块(例如 “fs”、”path”等)或者是一个本地相对路径(例如 ./module-a.js 或 /my-li/module-b.js),那么 Node 会直接使用对应的文件。 如果不是前面描述的情况,那么 Node 会开始寻找一个名为 node_modules 的目录: 首先 Node 会在当前目录寻找 node_modules,如果没有则到父目录查找,以此类推直到系统根目录。 找到 node_modules 目录之后,再在该目录中寻找名为 moduleName.js 的文件或是名为 moduleName 的子目录。 此处旨在说明问题,对 Node 内部模块解析逻辑做了简化描述
可见 Node 在解析依赖时需要进行大量的文件 I/O 操作,效率并不高。
再来看看安装依赖时发生了什么,现阶段 yarn install 操作会执行以下 4 个步骤:
将依赖包的版本区间解析为某个具体的版本号 下载对应版本依赖的 tar 包到本地离线镜像 将依赖从离线镜像解压到本地缓存 将依赖从缓存拷贝到当前目录的 node_modules 目录 其中第 4 步同样涉及大量的文件 I/O,导致安装依赖时效率不高(尤其是在 CI 环境,每次都需要安装全部依赖)。

这两天学习了一下 Flutter 中的 InheritedWidget 的使用方法,顺便查看一下相关源码了解了其底层实现机制。特地记录一下。
Prerequirements 由于本文主要是从源码的角度分析 InheritedWidget 的工作原理,所以对阅读本文的小伙伴的 Flutter 知识有一定的要求。主要有以下几点,如果其中某部分你还不太清楚,请先阅读相关链接:
了解 Flutter 的基本用法。 了解 Flutter 中的 Widget 和 Element 的基本概念。 推荐阅读:Flutter, what are Widgets, RenderObjects and Elements? 对 Flutter 中 Element 的生命周期有基本了解。推荐阅读:Element class 下面开始正文。
InheritedWidget 的使用方法 先看一个 InheritedWidget 最简单的使用示例:
import 'package:flutter/material.dart'; void main() => runApp(new MyApp()); class MyWelcomeInfo extends InheritedWidget { MyWelcomeInfo({Key key, this.welcomeInfo, Widget child}) : super(key: key, child: child); final String welcomeInfo; @override bool updateShouldNotify(InheritedWidget oldWidget) { return oldWidget.

在使用 Flutter 开发应用的过程中我们经常遇到需要展示一组连续元素的情景。这时我们通常会选择使用 ListView 组件。在电商场景中,被展示的元素通常是一组商品、一组店铺又或是一组优惠券信息。把这些信息正确的展示出来仅仅是第一步,通常业务同学为了统计用户的浏览习惯、活动的展示效果还会让我们上报列表元素的曝光信息。
什么是曝光信息? 什么是曝光是信息呢?简单来说就是用户实际看到了一个列表中的哪些元素?实际展示给用户的这部分元素用户浏览了多少次?
让我们通过一个简单示例应用来说明:
import 'package:flutter/material.dart'; class Card extends StatelessWidget { final String text; Card({ @required this.text, }); @override Widget build(BuildContext context) { return Container( margin: EdgeInsets.only(bottom: 10.0), color: Colors.greenAccent, height: 300.0, child: Center( child: Text( text, style: TextStyle(fontSize: 40.0), ), ), ); } } class HelloFlutter extends StatelessWidget { final items = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]; @override Widget build(BuildContext context) { return ListView.

蓝灯是个好工具。可以帮忙我们访问一些由于众所周知的原因在国内无法正常访问的网站(比如 Google、Stack Overflow、Medium 等等)。
每次启动蓝灯,它会自动修改操作系统的网络代理指向它自己。不需要我们手动配置,很是方便。
需要网络代理的地方其实不止是浏览器,很多命令行工具也会访问网络。比如,我们通过 homebrew 安装 dart 的时候,brew 命令会从 Google 的服务器上下载安装文件。然后你就会看到网络连接错误的提示信息。
要解决这类问题,只需要为 Shell 设置两个环境变量 HTTP_PROXY 和 HTTPS_PROXY 即可。我们直接利用蓝灯在本地启动好的代理端口。
我们首先找到蓝灯在本地启动的具体端口号。打开蓝灯,依次选择 Settings -> ADVANCED SETTINGS 即可看到蓝灯在本地选择的端口号。
然后去 Shell 里执行以下两个命令设置环境变量:
export HTTP_PROXY=http://127.0.0.1:51350 export HTTPS_PROXY=http://127.0.0.1:51350 就完成配置了。
最后为了避免每次都要敲这么长的命令,我们写一个 Shell 函数:
# http proxy util hp() { if [ "$1" = "enable" ] then PORT="51350" if [ -n "$2" ] then PORT="$2" fi export HTTP_PROXY=http://127.0.0.1:$PORT export HTTPS_PROXY=http://127.0.0.1:$PORT else export HTTP_PROXY="" export HTTPS_PROXY="" fi } 把这都函数代码放到 Shell 启动脚本里。然后需要开启代理的时候执行 hp enable 即可,或是指定代理端口号 hp enable 33333。关闭代理执行 hp 即可。